基于本体的金融知识图谱自动化构建 CCKS2020评测第五名方法总结与推广
在2020年CCKS(全国知识图谱与语义计算大会)举办的“基于本体的金融知识图谱自动化构建技术评测”中,我们团队提出的方案最终取得了第五名的成绩。该评测任务聚焦于金融领域,要求参赛者利用给定的非结构化文本和预定义的金融本体,自动化地抽取实体、关系及属性,以构建结构化的知识图谱。本文旨在我们的核心方法,并探讨其在更广泛场景下的推广潜力。
方法融合与迭代的自动化构建流程
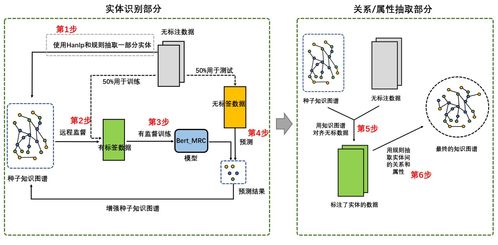
我们的方法并非依赖单一的模型或技巧,而是构建了一个多阶段、多模型协同的流水线系统,核心思想是“融合先验、迭代优化”。主要步骤如下:
1. 本体引导的实体识别与分类:
金融本体提供了严谨的概念层次和约束,这是宝贵的先验知识。我们采用基于BERT的序列标注模型进行命名实体识别(NER),但关键创新在于将本体中的类别信息(如“公司”、“金融产品”、“人物”)融入到模型的训练中。我们构建了一个本体感知的标签体系,并在输入层通过特殊标记或特征嵌入的方式,让模型“感知”到当前文本片段可能涉及的金融概念,从而提升了对专业术语和歧义实体的识别准确率。
2. 关系与属性的联合抽取:
针对金融文本中实体关系紧密交织的特点,我们没有将关系抽取和属性抽取完全割裂。我们设计了一个基于指针网络的联合抽取模型。该模型以识别出的实体对和上下文为输入,同时预测关系类型和属性值。这种方法能有效捕捉关系与属性之间的内在联系,例如,“A公司控股B公司(关系)”与“持股比例(属性)”常常同时出现,联合建模减少了误差传播。
3. 基于规则与一致性校验的后处理:
纯端到端的深度学习模型在处理复杂金融逻辑时仍有不足。我们引入了一个后处理模块,利用本体中定义的概念不相交性、属性值域等约束,以及人工的少量高质量规则,对自动抽取的结果进行校验和修正。例如,检查“成立日期”属性的格式是否符合时间规范,或根据“是...的子公司”关系推断并补全反向的“拥有子公司”关系,确保图谱的逻辑一致性。
4. 迭代式知识融合与自增强:
这是我们的核心优化策略。初始构建的图谱难免存在噪声和缺失。我们设计了一个轻量级的迭代流程:将首轮抽取结果中置信度较高的部分(如高概率实体和关系)作为“准知识”,反哺给后续的抽取模型。在第二轮处理时,模型能够参考这些已存在的知识来理解上下文,从而提升对模糊提及或长距离依赖关系的抽取能力。这种“抽取-融合-再抽取”的闭环,有效实现了系统的自我增强。
技术推广:超越金融领域的通用化启示
虽然本次评测聚焦金融,但我们的方法框架具有向其他垂直领域推广的普适价值。
- 领域适配性强:其核心在于“领域本体+深度学习+逻辑规则”的融合范式。对于医疗、法律、工业等任何拥有或可以构建领域本体的场景,只需将预训练模型(如BERT)替换为领域预训练模型(如BioBERT、Legal-BERT),并导入对应的领域本体,整个流水线的主体架构可快速复用。本体作为领域知识的“骨架”,确保了构建过程的方向性和专业性。
- 解决数据稀缺问题:在多数专业领域,高质量的标注数据稀缺。我们的方法通过充分利用本体(一种结构化知识)来引导和监督数据驱动的模型,降低了对海量标注数据的依赖。迭代自增强机制也能在一定程度上利用模型自身产出的高置信结果来扩充训练数据,缓解冷启动问题。
- 提升图谱质量与可用性:后处理中的一致性校验环节至关重要,它直接关系到产出图谱的逻辑质量,是知识图谱能否应用于风控、问答、推理等下游任务的关键。这一环节的设计思想可以推广到任何对数据质量要求严苛的应用中。
- 拥抱大模型时代的新机遇:在当前大语言模型(LLM)兴起的背景下,我们的框架可以进一步升级。例如,可以利用LLM强大的零样本/少样本理解能力,替代或辅助传统的NER和关系抽取模型,尤其是在处理复杂、隐含的关系时。本体则可以作为约束和引导LLM生成的结构化“思维框架”,确保其输出符合领域规范,避免“幻觉”,实现“大模型感知能力”与“本体领域知识”的强强联合。
###
在CCKS2020评测中取得第五名,是对我们提出的“本体引导、联合抽取、规则校验、迭代增强”技术路线的有效验证。该方法平衡了数据驱动与知识驱动的优势,在保证自动化程度的显著提升了金融知识图谱构建的准确性与一致性。其模块化的设计理念和融合核心思想,为在更多数据有限但知识丰富的垂直领域,进行高效、可靠的知识图谱自动化构建,提供了可借鉴、可推广的解决方案。结合大模型等新技术,这一框架有望释放出更大的潜力。
如若转载,请注明出处:http://www.dqryx.com/product/17.html
更新时间:2026-06-13 07:48:32